What Is AI Model Training?
Training an AI model is the process of feeding curated data to an algorithm so it can refine itself and produce accurate outputs. It teaches the system to recognize patterns in data and make predictions based on what it learns.
During training, examples are presented and the model’s internal parameters are adjusted iteratively. Over many iterations, the model gradually improves its ability to generalize. For example, an image classifier might be trained on thousands of labeled photos until it can reliably distinguish dogs from cats.
AI model training proceeds in many iterations. Each pass through the data updates the model’s parameters to correct errors, similar to how a student learns from feedback. The goal is to create a mathematical model that accurately produces the right output in diverse conditions.
In essence, AI training is like teaching a new skill: with enough examples and feedback, the system learns to make better decisions.
Why Train a Custom AI Model? (Why Not Just Use a Base Model?)
Generic pre-trained models can be useful starting points, but they often lack specialization for a specific task or dataset. Training your own AI model on domain-specific data tailors it to the nuances of your problem, which generally improves accuracy and relevance.
A generic model may misinterpret unique inputs or carry unwanted biases. By contrast, a custom-trained model learns exactly what you need.

For instance, you might take a broad pre-trained model and fine-tune it on your data, a process called transfer learning, so it performs well on your specific application. If no suitable base model exists, fully training a new model ensures it learns the exact patterns needed for your use case.
Is Training an AI Model the Same as Fine-Tuning?
Training an AI model is conceptually similar to fine-tuning, but the two approaches differ significantly in scope, cost, and purpose.
Training from scratch builds a model’s foundational knowledge using massive datasets and significant compute resources. Fine-tuning, on the other hand, adapts an existing pre-trained model on a smaller, specialized dataset to improve performance on specific tasks.
Think of it this way: training from scratch is like putting a student through a full university education, while fine-tuning is like enrolling that same graduate in a short professional certification course. Both result in learning, but at very different scales and starting points. Choosing between the two depends on whether a suitable base model already exists for your domain.
What Data Does an AI Model Need — and What Makes It High Quality?
Data is the fuel for AI model training. Without it, the model simply cannot learn. In practice, training requires large, well-prepared datasets that match your problem domain and cover all relevant scenarios.

Each example in the training set should be accurately labeled if using supervised learning. The quality, quantity, and diversity of the data are all critical factors.
Data Volume
- Models typically need thousands of examples per category to learn effectively
- A rough rule of thumb is about 5,000 labeled samples per class for basic performance
- On the order of 10 million examples may be needed to reach near-human accuracy
- More data generally leads to better results, as long as it remains relevant
Data Quality and Diversity
- The data must accurately reflect real-world conditions
- If an AI model is fed unvetted or homogeneous data, the results will be subpar
- Including diverse examples helps the model generalize beyond the training set and avoid bias
Labels and Format
- For supervised learning, each training example needs the correct label
- Data should be cleaned, normalized, and formatted consistently
- Imbalanced or incorrect labels will lead the model to learn wrong patterns, so careful annotation and balanced classes are essential
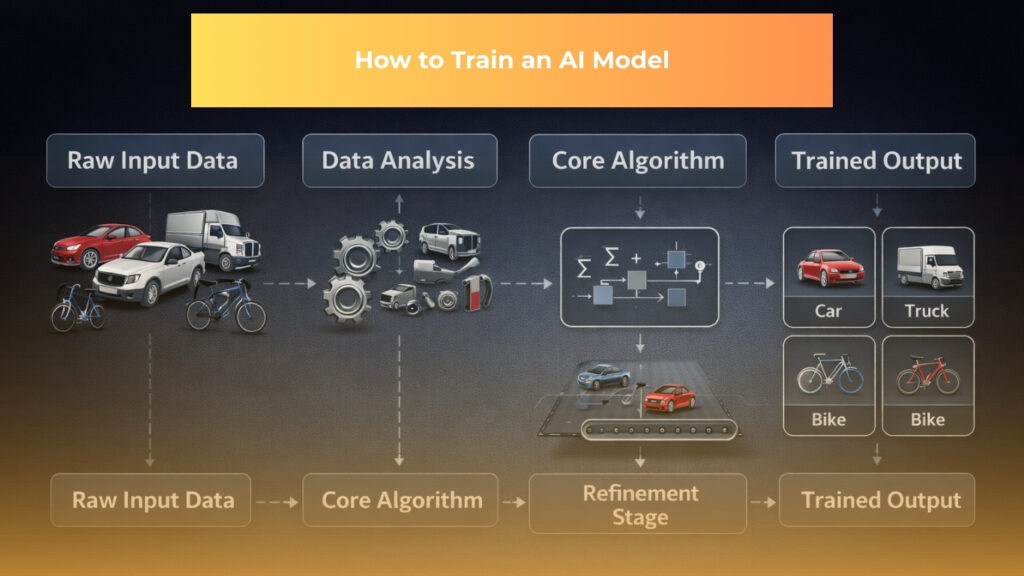
The Process of AI Model Training: Step by Step
The five core steps to train an AI model are: prepare your data, select a model, train it, validate and test it, then deploy and monitor it. Each step is covered in detail below.

Step 1: Collect Your Training Data
First, gather the raw data relevant to the task. This could be database records, text, images, sensor readings, and more. For example, anomaly detection in healthcare might use patient vital signs and lab results, while demand forecasting in retail might use historical sales and inventory data.
Aim to collect data that covers all conditions the model will face. Sources might include:
- Company databases and internal logs
- Sensors or connected devices
- Surveys or user submissions
- Publicly available datasets (e.g., Kaggle)
The more representative and varied your data, the better.
Step 2: Label and Prepare the Data
Next, clean and annotate the collected data. Training must begin with quality data that accurately and consistently represents real-world situations. This means removing errors, handling missing values, and formatting the data for your model.
If using supervised learning, annotate each example with the correct label, such as image categories or text sentiments. Also split the dataset into training, validation, and test sets. Well-prepared, high-quality data ensures the model learns the intended patterns.
Step 3: Choose Your Model Architecture and Begin Training
Now select an appropriate model and start training. The choice depends on your data type and goals:
- Convolutional neural networks (CNNs) are common for image tasks
- Regression models often fit numeric prediction problems
- Transformer models are widely used for natural language tasks
Once you choose a model, feed the training data into it in iterative rounds called epochs. During each round, the model processes inputs, makes predictions, computes errors, and adjusts its internal weights to improve. As training proceeds, track key metrics like loss or accuracy to ensure the model is learning.
Step 4: Validate and Test for Accuracy and Bias
After training, evaluate the model on unseen data. Use a validation or test set to measure accuracy, precision, recall, F1-score, and other relevant metrics.
It is also crucial to check for bias or fairness issues. Analyzing the model’s errors and class performance helps surface any systematic problems. Gartner reports that roughly 85% of AI projects deliver errors due to biases or data issues, so thorough evaluation is essential.
If accuracy is low or unfair behavior appears, such as misclassifying a minority group, you may need to gather more representative data or adjust the training process.
Step 5: Deploy, Monitor, and Refine with Feedback
Finally, deploy the model in production and continue learning from its performance. Once the model shows reliable results on test data, it can go live.
After deployment, developers should continue to monitor results for any anomalies that demand further refinement, because an AI model should be treated as a continuous project. In other words, track its real-world performance and gather feedback.
As one AI analyst notes, building the model is just the start: “deploying it, maintaining it, and proving its value in production… is where the real work begins.” Use new data and feedback to retrain or fine-tune the model over time, keeping it accurate and up to date.
How Hard Is It to Train an AI Model? (Challenges and Realistic Expectations)
Training an AI model is achievable, but it can be more challenging than it appears. It typically requires large amounts of data, specialized expertise, and computing resources.

Gartner found that roughly 85% of AI projects end up producing errors due to biases or data issues. Poor data quality or insufficient training examples are often the main culprits, as thousands to millions of labeled examples per category may be needed depending on the desired accuracy level.
Other common challenges include:
- Avoiding overfitting, where a model memorizes training data but fails to generalize
- Scaling the infrastructure to handle large datasets
- Iterating through multiple rounds of evaluation and retraining
On the positive side, many tools now simplify training. Platforms like Google’s Teachable Machine, Vertex AI, and open-source libraries like Hugging Face let beginners train basic models with minimal code. With realistic expectations around sufficient data, time, and iterative tuning, organizations of any size can train effective AI models.
Build Your Custom AI Model with HBLAB
Understanding how to train an AI model is one thing. Having the right partner to build, deploy, and scale it is another entirely.
HBLAB is a premier AI development outsourcing company helping organizations move from AI concept to production-ready reality. Whether you are starting from scratch or embedding intelligent capabilities into your existing platforms, HBLAB delivers end-to-end AI solutions tailored precisely to your business needs.

Their expertise spans the full AI development lifecycle:
- Generative AI solutions built on cutting-edge large language models, customized with your proprietary data for accurate, domain-specific outputs
- AI Agents and multi-agent systems orchestrated through their proprietary M Workspace platform, enabling autonomous digital workforces that handle complex, multi-step business processes
- AI capability integration embedded directly into your existing tools, workflows, and enterprise platforms without disrupting operations
Rather than offering off-the-shelf models, HBLAB treats every engagement as a co-development partnership, ensuring governance, compliance, and business rules are built into the model’s architecture from day one, not bolted on later.
With a team of Kaggle Experts ranked in the global top half percent, a nine-year R&D track record, and offices across Vietnam, South Korea, Japan, and Singapore, HBLAB combines deep technical precision with local market nuance.
For organizations ready to stop experimenting and start transforming, HBLAB offers a proven path to custom AI that is scalable, secure, and built around you.
FAQs
1. What does “train AI model” mean?
Training an AI model means teaching an algorithm to recognize patterns and make predictions using data. It involves feeding examples into the model so it can learn to produce correct outputs.
2. Can we train AI models?
Yes. With the right data and tools, anyone can train an AI model. Many frameworks like TensorFlow, PyTorch, and scikit-learn, as well as cloud AI platforms and low-code tools, allow users to build and train models on their own data.
3. Can I train my own AI image model?
Yes. To train an image model, gather and label a large set of example images for each category. Then use a machine-learning framework or tool to learn from them. For image recognition, you will need a large set of labeled photos. Modern tools like Google Teachable Machine or TensorFlow/Keras make it straightforward to train a custom image classifier once you have enough labeled images.
4. What are the 4 models of AI?
This commonly refers to the four broad learning approaches:
- Supervised learning uses labeled data to train predictions
- Unsupervised learning finds patterns in unlabeled data
- Reinforcement learning learns via rewards and penalties
- Generative learning creates new data outputs from large example sets
5. How do I train in AI as a beginner?
Start small and use beginner-friendly resources. Follow tutorials that walk through training a simple model, such as a basic image or text classifier. Use accessible tools like Google’s Teachable Machine, AutoML, or Kaggle notebooks to practice. Focus first on understanding your data and selecting a simple model, then gradually tackle more complex projects as your skills develop.
READ MORE: